Preface: The “Day Two” Challenge After Database and Table Sharding
In the architectural evolution of large-scale microservices, database and table sharding is often regarded as the “silver bullet” for solving massive data storage and high-concurrency write challenges. When we excitedly use Apache ShardingSphere to split a monolithic database into 16 sharded databases and 1,024 sharded tables, watching system throughput soar, we often overlook a serious problem that follows closely—operations and consistency. On the “day two” after sharding goes live, development and operations teams typically face the following soul-searching questions:
- DDL Nightmare: When business requirements change and a field needs to be added to a logical table, must the DBA manually connect to 16 databases and execute
ALTER TABLE1,024 times? - Microservice “Split Personality”: In a microservices multi-instance deployment scenario, if instance A modifies the table structure, how does instance B know? If instance B doesn’t know and is still using old metadata to assemble SQL, won’t it throw errors?
- Architecture Selection Confusion: I’ve heard that ShardingSphere has both JDBC and Proxy modes. Do we also need to introduce Zookeeper? Won’t this make the architecture too complex?
Based on practical experience, this article will systematically dissect the problem, from DDL change consistency to microservice metadata synchronization, providing a complete solution.
Part I: How to Elegantly Manage Hundreds or Thousands of Tables?
In the era of monolithic databases, executing an ALTER TABLE was a simple task. However, in a sharding architecture, a logical table (Logic Table) may correspond to dozens or even hundreds of physical tables (Actual Tables) scattered across different physical nodes. If manual maintenance is adopted, not only is efficiency extremely low, but it’s also very easy to have “missed cases”—where some sharded tables succeed while others fail, leading to Schema inconsistencies between data nodes and causing catastrophic errors at the application layer.
Solution: ShardingSphere-JDBC + Flyway / Liquibase
In the Java ecosystem, it’s recommended to combine ShardingSphere-JDBC with database version management tools such as Flyway or Liquibase.
The core process is as follows:
- Write Once: Developers only need to write a standard SQL change script (e.g.,
V1.0.1__add_column_to_user.sql) as if working with a single database. - Version Management: Place the script in the project’s
resources/db/migrationdirectory and include it in Git version control. - Automatic Execution: When the application starts, Flyway automatically handles database migration.
- Transparent Broadcasting: This is the most critical step. Flyway doesn’t connect to the real physical data source, but rather to the logical data source provided by ShardingSphere-JDBC. ShardingSphere-JDBC internally intercepts this DDL statement, recognizes it as a change to a logical table, and then uses its core capabilities to automatically broadcast this DDL to all related underlying physical sharded databases and tables.
Example diagram:
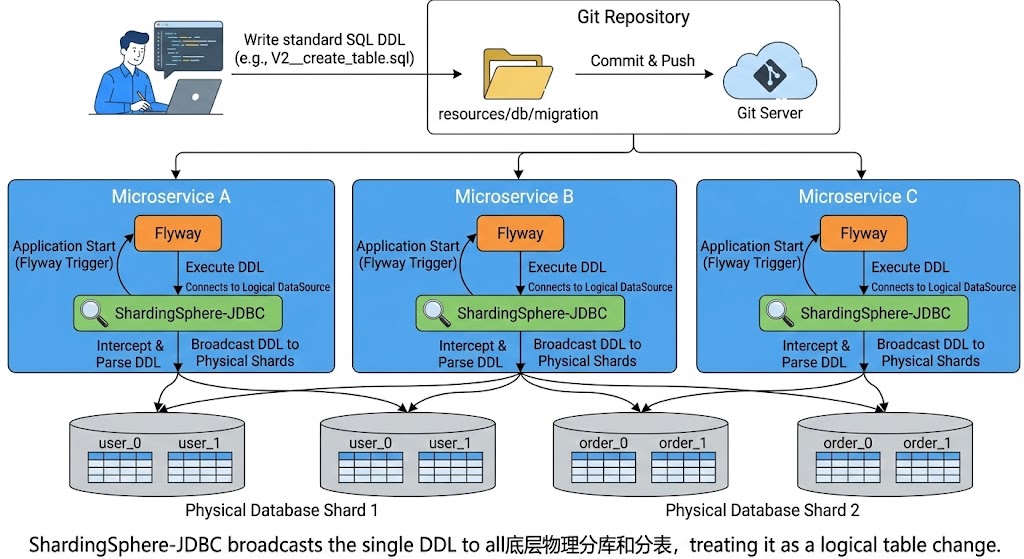
Why is this approach a best practice?
- Development Transparency: Developers don’t need to care about how many databases or tables are sharded at the bottom layer. The mental model is no different from single-database development.
- Atomicity Guarantee: ShardingSphere will execute these DDLs in parallel and attempt to ensure consistency of execution results.
- Automation: Combined with CI/CD processes, fully automated database releases can be achieved, completely eliminating manual DBA operations.
Part II: Why Isn’t Standalone Mode Enough?
After solving the DDL execution problem, we successfully updated the structure of all physical tables through Flyway. However, in a microservices architecture, a new, more hidden “pitfall” emerges.
What is Standalone Mode?
ShardingSphere-JDBC runs in Standalone (single-machine) mode by default. The characteristics of this mode are:
- Configuration Isolation: Each microservice instance reads its local YAML configuration file at startup.
- Static Loading: At startup, the instance connects to the database, loads the table structure (metadata), and caches it in its own JVM memory.
- No Communication: Instance A and Instance B have no connection with each other. They each maintain their own set of “sharding rules” and “metadata”.
Scenario Reproduction: “Data Blind Zone” in Microservices Environment
Suppose we have a microservice User-Service deployed with three instances for high availability: Node A, Node B, and Node C.
- Change Occurs: Traffic is routed to Node A, triggering Flyway to execute DDL (e.g., adding field
age). - Local Refresh: After ShardingSphere-JDBC on Node A executes the DDL, it intelligently refreshes the metadata in its own memory. At this point, Node A knows the table structure has changed.
- Silent Crisis: Node B and Node C did not execute the DDL (because Flyway ensures it only executes once), and they are completely unaware. In their memory, the table structure is still old.
- Failure Eruption: When a new request carrying data with the
agefield is routed to Node B, Node B generates SQL based on old metadata, or cannot map the new field when processing the result set, directly throwing an exception.
Example diagram:
This is the limitation of Standalone mode: it cannot share runtime metadata state across services and instances. It’s only suitable for scenarios where configuration never changes, or for monolithic applications.
Part III: Cluster Mode (Zookeeper / Etcd) for Metadata Coordination
To solve the “split-brain” problem in the microservices environment described above, we need to introduce a coordinator—this gives birth to ShardingSphere’s Cluster mode.
3.1 What is Cluster Mode?
Cluster mode introduces a third-party distributed coordination center (Registry Center), currently supporting Zookeeper and Etcd as mainstream options. In Cluster mode, ShardingSphere-JDBC instances are no longer isolated islands but form a coordinated cluster. It solves two core problems:
- Metadata Consistency
- Multi-Instance Coordination
Concept to Clarify: DDL Broadcasting ≠ Cluster Mode
Many people easily confuse these two concepts:
- DDL Broadcasting: Refers to how SQL statements are distributed to physical databases. This can work in Standalone mode as well.
- Cluster Mode: Refers to how sharding rules and metadata state are synchronized between different application instances.
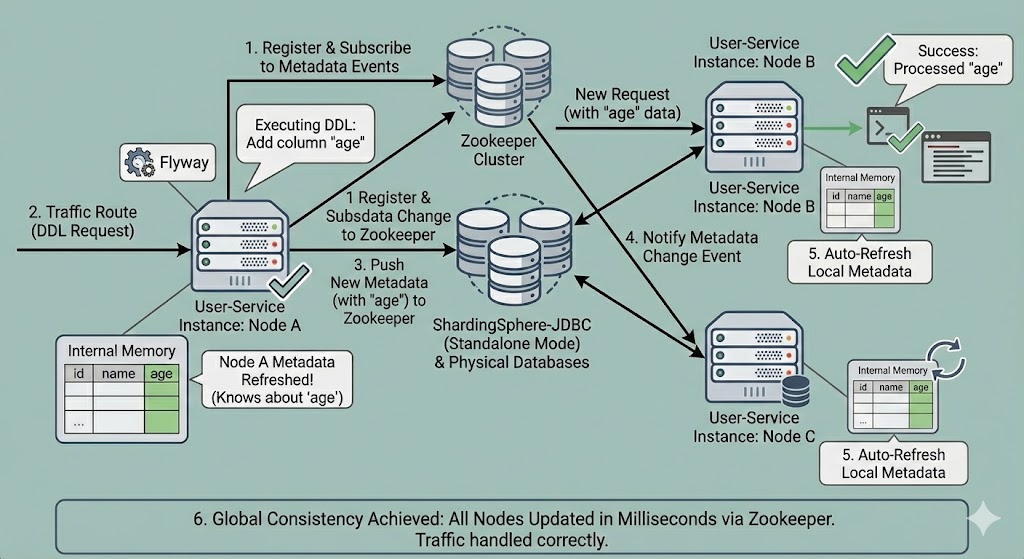
How Cluster Mode Works: Let’s return to the previous microservices scenario and see what changes occur after introducing Zookeeper:
- State Registration: All service instances (Node A, B, C) register with Zookeeper at startup and subscribe to metadata change events.
- Change Trigger: Node A executes DDL.
- Synchronization Center: After Node A completes execution, it not only refreshes the local cache but also writes the latest metadata structure to Zookeeper.
- Event Notification: Zookeeper detects node data changes and immediately pushes “metadata change events” to Node B and Node C, which have subscribed to that node.
- Automatic Refresh: After receiving notifications, Node B and Node C automatically reload metadata and update local memory.
- Global Consistency: The entire system achieves state consistency within milliseconds. No matter which node traffic hits, it can correctly handle the latest table structure.
Example diagram:
Why Must Microservices Architecture Use Cluster Mode?
In summary, as long as your system meets the following characteristics, Cluster mode is a must:
- Multi-Instance Operation: The same service is deployed with multiple replicas.
- Dynamic Requirements: DDL changes may occur at runtime, or read-write separation nodes may be dynamically enabled/disabled.
- Strong Consistency Requirements: Cannot tolerate SQL errors caused by metadata delays.
By using Zookeeper/Etcd as the configuration center and metadata center, we achieve:
- Distributed Transaction Coordination
- Distributed Metadata Sharing
- Dynamic Data Source Updates (e.g., circuit-breaking a slave database)
- State and Monitoring Sharing
Part IV: Do We Need to Introduce ShardingSphere-Proxy?
After solving DDL and metadata synchronization, many architects will have a new question: “Do I need to introduce ShardingSphere-Proxy, this independently deployed middleware?”
First, we need to understand the positioning and advantages of Proxy. ShardingSphere-Proxy is positioned as a transparent database proxy. It looks like a database and works like a database.
Its main advantages are:
- Multi-Language Support: If your backend technology stack is mixed, with Java, Python, Go, Node.js, PHP, etc. Non-Java languages cannot use JDBC Driver, so Proxy is the only choice. It exposes services through MySQL/PostgreSQL protocols, allowing clients in any language to connect directly.
- Connection Management: Proxy can serve as a connection pool, reducing connection pressure on underlying physical databases.
- Unified Entry Point: For DBAs and operations personnel, connecting to Proxy for queries and management is more convenient than directly connecting to physical databases or configuring complex JDBC.
So, Why Isn’t Proxy Needed in Pure Java Ecosystems?
Although Proxy is powerful, it also introduces additional architectural complexity and deployment/operations costs. If your team matches the following profile, you don’t need to introduce Proxy at all:
- Full-Stack Java: Backend services are primarily based on Java (Spring Boot / Spring Cloud).
- Mature Microservices Orchestration: Already has a complete microservices governance system.
- No Multi-Language Requirements: Don’t need Python scripts or PHP web pages to directly connect to databases and operate on sharded data.
- DBA Needs Met Through Other Means: DBAs can perform operations through specialized tools or temporary Proxy instances, without production traffic going through Proxy.
In a pure Java microservices architecture, ShardingSphere-JDBC + Cluster Mode (ZK/Etcd) + Flyway is the lightest-weight, highest-performance, lowest-maintenance-cost golden combination. JDBC mode itself has all the core capabilities of database/table sharding, DDL broadcasting, read-write separation routing, merging, and distributed transactions, with extremely low performance overhead (nearly native JDBC).
Part V: Summary
The problem of maintaining data consistency after database and table sharding in microservices is essentially a distributed system state synchronization problem. The following solutions are provided:
- Solving “Database/Table Structure” Consistency: Don’t hesitate to use Flyway or Liquibase. Script and version DDL, leverage ShardingSphere-JDBC’s broadcasting capability to achieve “write once, execute everywhere”.
- Solving “Inter-Instance” Consistency: In microservices multi-instance scenarios, Cluster mode must be enabled. Introduce Zookeeper or Etcd to establish a metadata center, ensuring that when one instance modifies the database structure or state, all other “sibling instances” can receive notifications in real-time and synchronize updates.
- Architectural Simplification: If business scenarios are primarily based on JVM languages, don’t blindly introduce ShardingSphere-Proxy. Stick with JDBC mode, which provides better performance and a simpler topology.
Through this combination—JDBC + Flyway + Cluster Mode—we can build a modern database architecture that has both elastic scaling capabilities and a monolithic application-like development experience. This not only solves the operational pain points after sharding but also lays a solid foundation for the system’s long-term evolution.