In the world of concurrent programming, “thread safety” usually means “locking”. From the synchronized keyword to ReentrantLock, we’ve grown accustomed to ensuring data consistency by exclusively locking resources. However, locks are not a silver bullet. In scenarios pursuing extreme performance, the context switching and waiting costs brought by locks can become system bottlenecks. So, is there a way to safely modify shared variables across multiple threads without suspending (blocking) threads?
The answer is yes. This is atomic variables and non-blocking synchronization algorithms (Non-blocking Algorithms), commonly known as optimistic locking.
Part I: The Cost of Locks
In traditional concurrency models, we primarily rely on blocking locks. This mechanism is also called pessimistic locking: it assumes the worst-case scenario, believing that if resources aren’t locked, other threads will definitely cause trouble. Although locks can ensure safety, in high-concurrency scenarios, they bring two significant performance killers:
- Thread Suspension and Recovery Overhead: When a thread cannot acquire a lock, it is blocked (suspended). The operating system needs to perform context switching when suspending and resuming threads, which is an extremely expensive operation in high-performance scenarios.
- Liveness Issues: Blocking locks can lead to deadlocks, priority inversion, and thread starvation.
For simple counter increment operations, suspending and resuming threads for this purpose is like shutting down an entire city’s water supply system just to drink a glass of water—the cost is extremely disproportionate. For scenarios involving integer and object reference changes, what we need is a lighter-weight, more “optimistic” approach.
Part II: Hardware-Level Atomic Weapon: CAS
Java 5.0 introduced the java.util.concurrent package. The secret weapon behind the performance leap of atomic classes (such as AtomicInteger) and non-blocking data structures (such as ConcurrentLinkedQueue) is the CAS (Compare-And-Swap) instruction.
What is CAS?
CAS is a hardware primitive directly supported by CPU instruction sets (such as x86’s lock cmpxchg). It embodies the philosophy of optimistic locking: I don’t lock, I directly attempt to update; if the update fails (meaning someone else got there first), I retry or give up, but I never suspend myself.
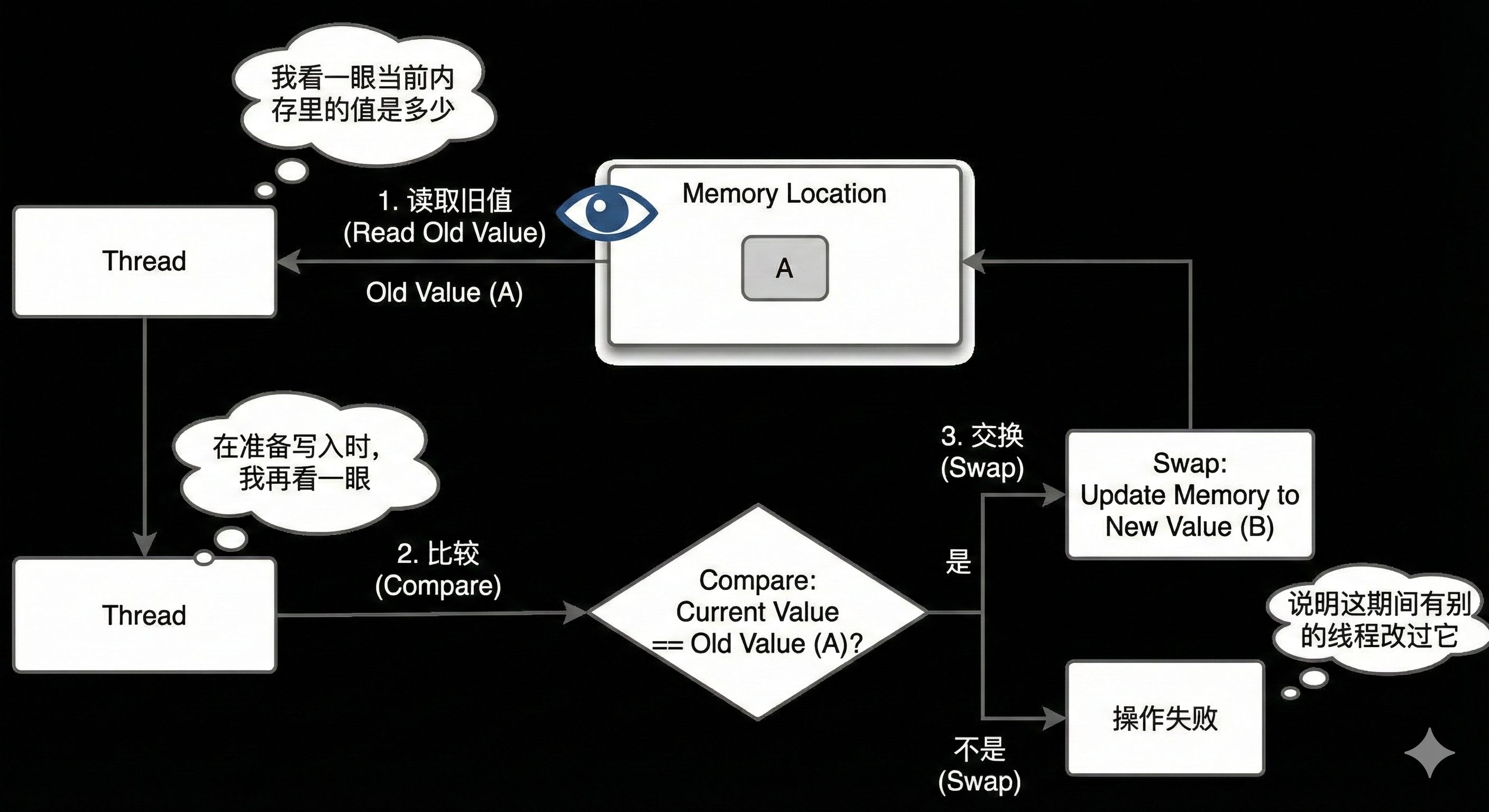
CAS operations consist of three core steps:
- Read Old Value: I take a look at what the current value in memory is.
- Compare: When preparing to write, I take another look—is the value in memory still the same one I saw earlier?
- Swap: If yes, I update it to the new value (New Value); if not, it means another thread modified it during this time, and my operation fails.
We can use a piece of Java code to simulate CAS logic (Note: Real CAS is a lock-free CPU instruction; using synchronized here is only to simulate its atomic semantics):
@ThreadSafe
public class SimulatedCAS {
@GuardedBy("this") private int value;
// Only update to newValue if the value in memory equals expectedValue
public synchronized int compareAndSwap(int expectedValue, int newValue) {
int oldValue = value;
if (oldValue == expectedValue)
value = newValue;
return oldValue;
}
}
Why is CAS Faster Than Locks?
The cost of locks is waiting (thread blocking), while the cost of CAS is retrying (CPU spinning). In most cases, for the CPU, the cost of retrying a few instructions is much lower than the cost of suspending and scheduling threads.
To use CAS, you must meet two prerequisites:
- Hold the Old Value: You must know which version of data you’re modifying based on.
- Be Able to Calculate the New Value: CAS is “compare + replace”; you must prepare the new value before the operation.
Once we master CAS, we can build non-blocking algorithms (Non-blocking Algorithms). The characteristic of such algorithms is: the failure or suspension of one thread does not prevent other threads from working.
Taking a non-blocking stack (Treiber Stack) push operation as an example, we can see how CAS works:
- Read: Get the current top node
oldHead. - Calculate: Create a new node
newHeadand makenewHead.nextpoint tooldHead. - CAS: Atomically attempt to replace the stack top from
oldHeadtonewHead.- Success: Push operation completed.
- Failure: It means another thread modified the stack top between step 1 and step 3. No problem, re-read the new stack top and repeat the above process.
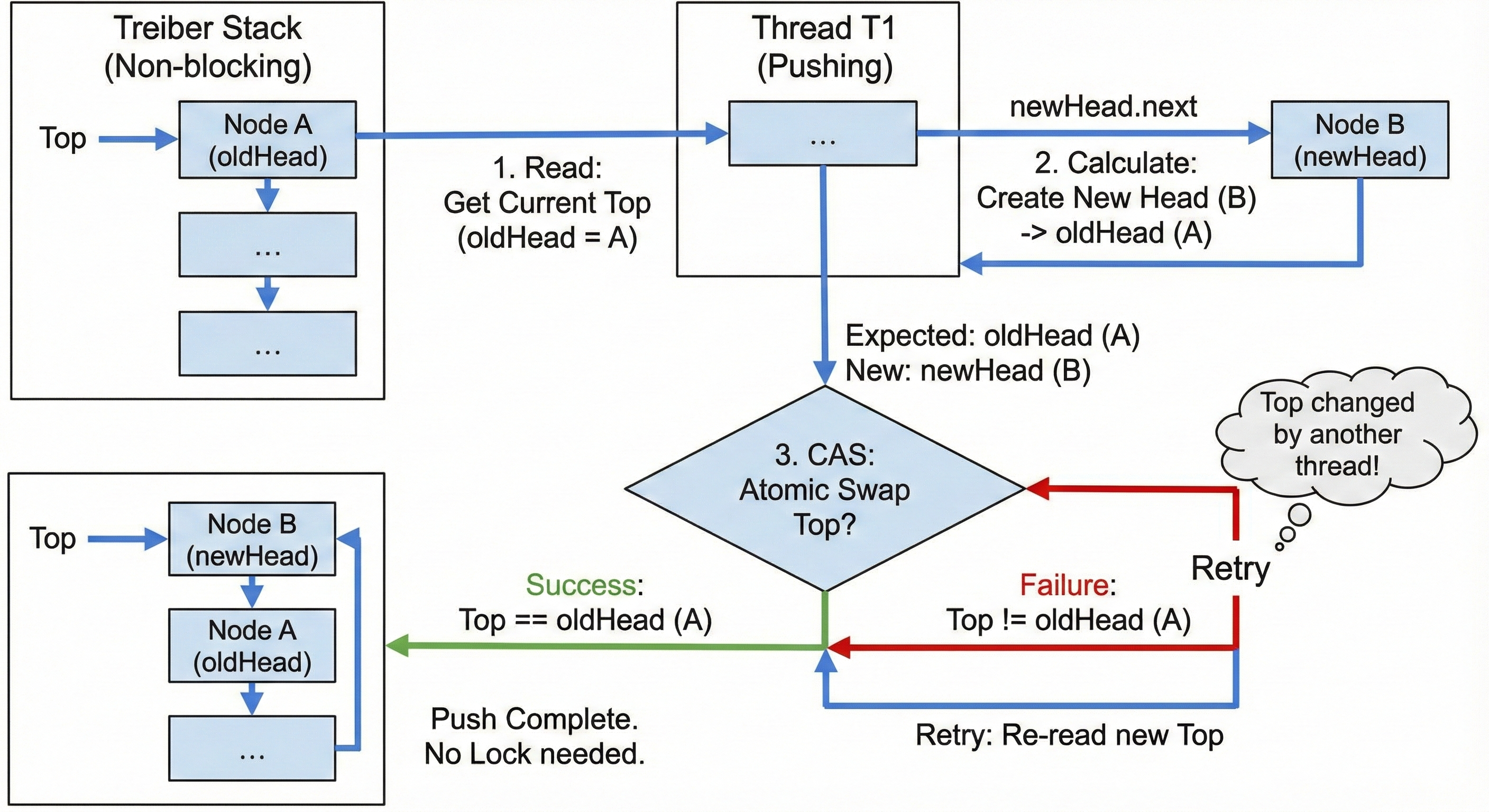
This approach requires no locks at all. All threads run at full speed, and no thread is suspended by the operating system, achieving extremely high concurrent performance.
Part III: CAS Pitfall: The ABA Problem
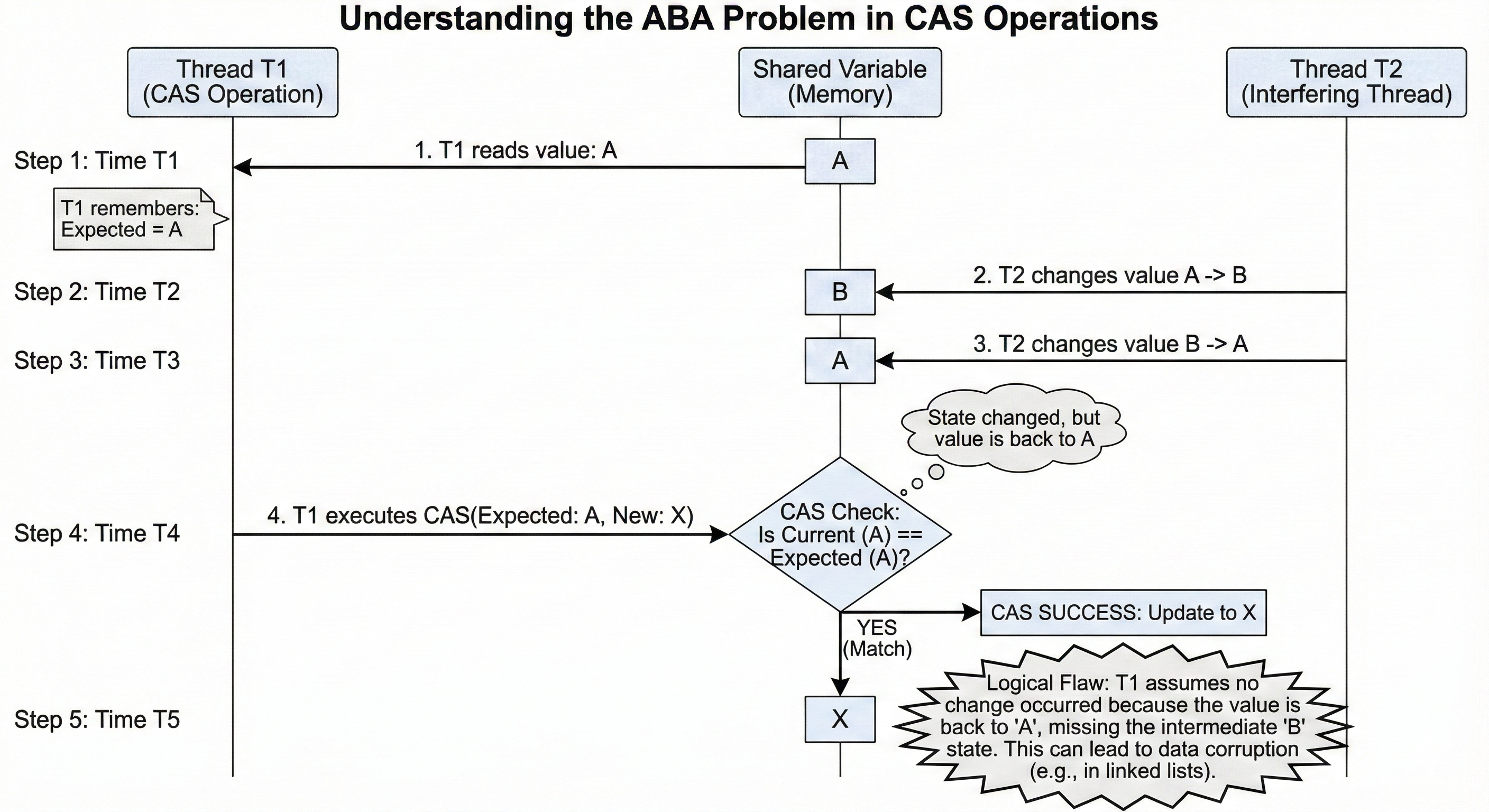
Although CAS is powerful, it has a logical flaw: it only compares whether “values” are equal, not whether “the value has been modified”. This is the ABA problem.
What is ABA?
Imagine the following scenario:
- Thread T1 is about to execute CAS, and it sees the variable’s value is A.
- Thread T2 acts quickly, changing the variable from A to B, then back to A.
- Thread T1 executes CAS, finds the variable’s value is still A, and therefore determines “data unchanged”, and the CAS operation succeeds.
In certain scenarios (especially involving pointer reuse or linked list node management), this can lead to serious data structure corruption. Although the value appears unchanged, “this A is not that A”—the intermediate state changes are lost.
How to Solve the ABA Problem?
The core idea to solve the ABA problem is to add versioning. If we not only update the reference but also update a version number simultaneously, the problem is solved:
- Without versioning:
A -> B -> A, CAS cannot detect it. - With versioning:
1A -> 2B -> 3A. During CAS checking, it will find that although the value is still A, the version number changed from 1 to 3, so the operation fails.
Java provides the AtomicStampedReference class to implement atomic reference updates with version numbers, completely solving the ABA problem.
Part IV: CAS in the Era of Virtual Threads
Reviewing the entire article, we can conclude: CAS is the cornerstone of high-performance concurrency. It avoids heavyweight locking mechanisms and achieves efficient thread safety using CPU-level instructions. All atomic classes in Java (AtomicInteger, AtomicReference) and high-performance queues (ConcurrentLinkedQueue) depend on it at the bottom layer. In the new era of Java 25 + Virtual Threads, is CAS’s position still solid?
The answer is: CAS remains the core at the bottom layer, but its dominance at the business layer has somewhat declined.
With the introduction of Project Loom (Virtual Threads), the cost of thread blocking has become extremely low (only suspending virtual threads, not kernel threads). In scenarios with extremely high contention, simple locks may save more CPU resources than CAS in intense spinning states. However, regardless, CAS remains the most fundamental primitive for JVM internal implementation and high-level concurrency abstractions (such as Virtual Threads scheduling itself). Understanding CAS is understanding the physical laws of concurrent programming.